


Voici à quoi ressemblera le passage de l’ouragan I.A. sur l’information
Les “Gafam+” vont considérablement modifier le paysage médiatique mondial qui devra se réinventer en profondeur. Voici les phases-clés de l’enchaînement.


• • • La version bullet points :
• En signant des accords de licence pour l'utilisation de leur production éditoriale, les médias risquent de faire gagner 2 à 3 ans aux géants de l’I.A.
• Ceux-ci vont chercher à prendre leur autonomie par rapport aux fournisseurs d’information.
• Cela se fera par la création de données synthétiques, et par un apprentissage des modèles qui deviendront des super-crawlers à même de détecter les informations de qualité librement accessibles.
• Une énorme bataille juridique s’annonce sur la propriété intellectuelle de tout ce qui sera dérivés de ces accords.
• • • La version Longue
Voici le scénario probable de “L’ère de l’I.A.”appliqué au paysage médiatique global, en six étapes.
Phase 1 : Apprentissage massif des “Gafam+”* à partir les données des médias. (*Par Gafam+, j’entends la Big Tech élargie aux nouveaux venus de l’I.A., les deux ayant d’ailleurs tendance à se confondre).
Cette phase est bien avancée car OpenAI et autres ont depuis longtemps pillé les médias de qualité (cf. la plainte déposée par le NYTimes, PDF ici). Ceux-ci auraient pu se rebiffer et poser la discussion en demandant collectivement des centaines de millions de dollars de dommages et intérêts au moyens d’une série d’actions en justice lancées des deux côtés de l’Atlantique, mais cela supposait une vision commune et une coordination qui n’existent pas dans le secteur des médias.
Grâce à une série d’accords préventifs inspirés de la désastreuse expérience de Google qui a mis dix ans avant de prendre conscience du problème, OpenAI a obtenu des licences qui lui feront gagner deux ou trois ans sur sa capacité à comprendre et à générer le news. Pour OpenAI (et Microsoft, son actionnaire et partenaire technique), c’est un excellent deal : moyennant un montant équivalent à quelques pourcents de son chiffre d’affaires, il obtient un accès illimité sur plusieurs années à ce qui s’apparente à du caviar pour des modèles d’I.A. gavés jusqu’ici de surimi et de nourriture industrielle : les flux des grands médias par opposition aux forums Reddit. Le saut qualitatif sera spectaculaire.
Phase 2 : Les brokers entrent dans le jeu. Les grands médias ont ouvert la voie de la capitulation générale. Au cours des 18 mois à venir, les accords de licence vont se multiplier car de nouveaux intermédiaires vont surgir. Ces brokers proposeront des licences donnant accès à des données de qualité, retraitées, clean, etc. Ils devraient logiquement élargir le spectre des supports inclus dans ces accords. Pour l’instant, le choix s’est fait selon l’équation suivante :
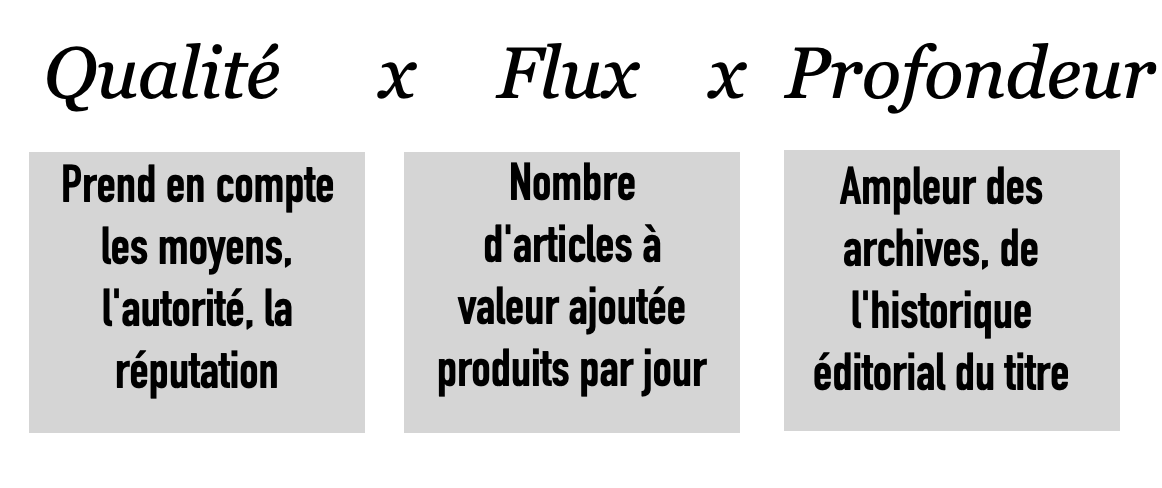
L’inclusion d’éditeurs de 2e tiers produisant de l’information à valeur ajoutée permettra d’ajouter de la diversité. (Je reviendrai sur le sujet des nouveaux intermédiaires de données dans quelques semaines après avoir enquêté sur un acteur européen spécifique).
Phase 3 : La création de données synthétiques. Une fois ces pipelines de données de qualité mis en place, les opérateurs d’I.A. vont créer d’immenses jeux de données artificielles, dérivées ce que les grands médias leur fourniront. Ces nouveaux datasets seront à même de reproduire toutes les caractéristiques — style rédactionnel, structure, typologie — des articles originaux. Les modèles gagneront en performance sur leur capacité à imiter la production des médias. Les entreprises d’I.A. seront plus autonomes par rapport à leurs fournisseurs
(cf. § 6 ⬇︎, le bétonnage juridique)
Phase 4 : La création de super crawlers. Toujours dans le but de réduire leur dépendance face à leurs fournisseurs, les modèles vont aussi apprendre à aller chercher l’information gratuite. Exemple : Le Monde publie un récit épatant, narrant les tractations au sein de la gauche pour dégager un premier(e)-ministrable. Bonnes infos, récit bien enlevé, etc. Très bien.
Aujourd’hui, en vertu de l’accord de licence passé avec OpenAI, celui-ci peut se servir de l’enquête pour nourrir les réponses aux questions des utilisateurs avides de politique. Temps de latence entre la publication du papier et son ingestion par GPT : quelques minutes.
Maintenant, admettons que l’accord n’existe pas ou plus. L’enquête publiée par Le Monde est de facto interdite d’utilisation. Mais les infos qu’elle contient sont reprises par un grand nombre de sites gratuits, voire par d’autres médias avec lesquels OpenAI a toujours un accord. Le deal est terminé avec Le Monde ? Dans les 12 heures qui suivent la publication de l’article, les éléments les plus saillants sont partout. GPT version 5 ou 6 sait où les trouver ; il a établi son catalogue de sites secondaires en fonction de leur qualité —car il sait détecter la qualité éditoriale*. (*J’ai travaillé deux ans sur le sujet, bien avant l’ère des LLM ; avec le projet Deepnews, nous avions obtenu des résultats prometteurs grâce à un réseau neuronal convolutionnel de 25 millions de paramètres contre plusieurs milliards pour le plus petit modèle de langage actuel).
Mieux : le papier du Monde est repris par un média avec lequel OpenAI a signé un accord comme une agence presse ou même Politico qui fait partie du groupe Axel Springer, le premier signataire d’un accord de licence avec OpenAI. Certes, cette agrégation aura quelques heures de retard sur le cycle de l’info, mais peu importe si elle est en mesure de servir une requête du type, “Résume-moi comment untel a été choisi par le NFP comme premier ministre potentiel”.
Cette terrible mécanique met à mal le mythe de l'information exclusive que les I.A. ne sont pas capables de produire” ; certes, il faudra toujours des reporters à la fois experts et courageux pour raconter avec émotion le quotidien de Kiev ou Gaza. Mais l’élément atomique de l’information va connaître une “commoditization”, une dilution qui va nous faire regretter l’époque de Google et de ses liens bleus.
Phase 5 : le renouvellement des licences. Les deals actuels entre les médias et les opérateurs d’I.A. sont signés pour trois ou quatre ans. Le renouvellement des accords-produits avec Meta ou Google — qui se font, aux dires des médias, dans des conditions bien plus difficile — donne un aperçu de ce qui attend le secteur lorsqu’il s’agira de reconduire ces deals. Pour les raisons évoquées plus haut, la Big Tech sera en position de dicter ses conditions. Outre les critères évoqués plus haut, l’un des facteurs sera le poids politique du média, sa capacité de nuisance en matière de communication. En d’autres termes, OpenAi ne prendra pas trop le risque de se fâcher avec le Financial Times ou Le Wall Street Journal dont l’hostilité pourrait influencer la perception des gouvernements et des régulateurs. L’équation évoquée plus haut se trouvera donc modifiée comme suit :

Phase 6 : Coulage d’un robuste béton juridique. Les géants de l’I.A. s’y préparent et ils ont les troupes pour cela : Microsoft emploie plus de 500 lawyers (1500 personnes en comptant tout le staff juridique) et Google 900. Sans compter le recours à des cabinets indépendants ultra-spécialisés.
Ce verrouillage va s’effectuer de deux façons :
• Une défense systématique du fair use, notion bien plus étendue aux Etats-Unis qu’en Europe. C’est en tout cas la petite musique qu’on entend partout Outre-Atlantique. Un indice récent : les propos de Mustafa Suleyman, chargé de l’I.A. chez Microsoft. Lors du festival Aspen Ideas fin juin, il exposait froidement le fait que, selon lui, le “contrat social” autour du numérique suggérait que tout est du domaine du fair use (timing dans la vidéo : 14’22”) avec cette perle : “L’économie de l’information va changer radicalement, car nous allons réduire à zéro le coût marginal de production de l’information” (il parle de la connaissance en général, pas de l’actualité). Nous voilà prévenus.

• La seconde couche de cimentage juridique est plus subtile : l’entraînement d’un modèle de langage à partir d’articles de presse (ou de tout autre type de données) suppose une série de transformations complexes et coûteuses : nettoyage des données, conversion en vecteurs numériques (le langage des algorithmes), création de word embeddings qui sont la représentation mathématique du maillage sémantique entre les mots. Juridiquement, il s’agit bien d’une transformation qui peut s’apparenter à une création originale, avec donc un transfert de la propriété intellectuelle au bénéfice de l’entité auteure de la transformation. C’est en tout cas la position que la Big Tech américaine va défendre, avec de bonnes chances de succès. Je reviendrai prochainement sur ce sujet complexe, en essayant entre autres de voir s’il suscite un début de réflexion à Bruxelles et chez nos croisés du souverainisme numérique tricolore.
• • •
Pour ceux qui en doutaient encore, l’I.A. sera un ouragan catégorie 5 pour l’industrie des médias, là où l’ère des Google et Facebook n’était qu’une tempête tropicale.
Le sort du news est-il pour autant scellé ? Certainement pas. Je reste certain qu’il y a de la place pour des médias à forte identité et qui sauront développer un business model solide en marge du magma informationnel issu des I.A. génératives. Mais il est temps de repenser radicalement la façon dont l’information est produite et distribuée. Ce sera le thème de la prochaine édition d’Episodiques.
Car entre temps la lutte continue.
Merci pour votre temps.
— frederic@episodiqu.es